Last time I shared how I was dipping my toes into reinforcement learning with my “side side quest” project. I had just set up the environment and was waiting on benchmark results to decide whether RL was worth pursuing for my hypothesis validation component. Well, a lot has happened since then - some promising developments and some humbling reality checks. Let me take you through the journey.
The Benchmark Results: Decision Time
After running the full 30-hour benchmark evaluation, I finally had concrete numbers to work with:
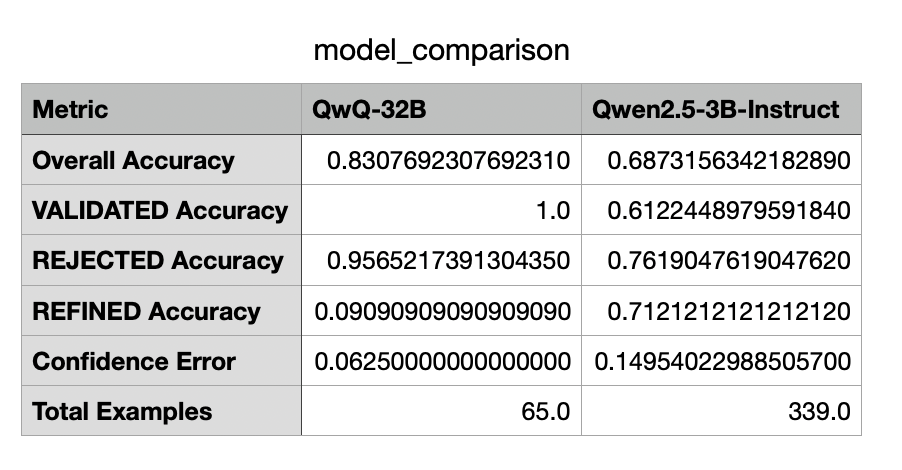
These results were fascinating. The QwQ-32B model crushed it on VALIDATED and REJECTED categories, but performed terribly on REFINED cases. Meanwhile, the much smaller 3B model showed more balanced performance across categories, although lower overall.
According to the decision framework I created with Claude’s help, the 3B model’s 69% accuracy placed it firmly in the “<70% accuracy” category - making it a perfect candidate for extended RL training. This aligned perfectly with my project plan’s criteria.
What’s more, I found a recent Stanford study suggesting that Qwen2.5-3B models are particularly well-suited for reinforcement learning. The paper showed these models “far exceed” similarly-sized models under identical RL conditions due to their natural tendency toward key cognitive behaviors like verification and backward chaining.
As I noted in my decision log: “The gap between model sizes (3B vs 32B) presents an opportunity to study whether RL can help a smaller model close the performance gap with a larger model.”
The RL Implementation Plan
With the benchmark supporting my hypothesis, I dove deep into planning the RL implementation. I decided to use Group Relative Policy Optimization (GRPO) since it:
- Uses relative rewards within groups to improve learning efficiency
- Reduces variance through group-based normalization
- Performs well with limited high-quality examples (my use case)
Here’s how I initially configured GRPO for my specific hardware and task:

I spent hours designing a custom reward function targeting the specific weaknesses of the Qwen2.5-3B-Instruct model:
See pseudo-code:

The reward function incorporated multiple components:
- Base reward for correct classification
- Extra bonus for VALIDATED decisions (our weakest category)
- Confidence calibration rewards
- Evidence utilization scoring
- Length penalties for verbosity
I also set up a detailed evaluation pipeline with confidence intervals, calibration curves, and statistical significance testing. This would tell me if improvements were meaningful or just random variation.
Getting Expert Feedback
One interesting thing I did at this point was to take my design document and ask Claude to help me craft a critique request. I wanted to get expert feedback on my approach before investing the time in implementation.
Claude generated a detailed request that included all the context an expert would need, highlighting that I was especially looking for input on:
- GRPO Configuration (batch sizes, KL penalties)
- Reward Function Design (weighting, potential for reward hacking)
- Evaluation Methodology (validation split, metrics)
- Technical Approach (Apple M4 Max optimizations)
I sent this critique request to ChatGPT Deep Research and received an amazingly detailed analysis. The critique went line by line through my implementation plan, offering both validation of my approach and suggestions for improvement.

For example, the expert confirmed my batch size of 16 was reasonable for my hardware but recommended profiling during early training to potentially increase it if my GPU wasn’t fully utilized. They also noted my KL penalty (β = 0.05) was on the lower side, suggesting I implement adaptive KL monitoring to adjust β if the model started to diverge too much from the reference.
On the reward function front, they validated my weighting structure but warned of potential issues:
- The model might game confidence calibration by being mildly confident on everything (0.5-0.7 range)
- My evidence utilization reward could be exploited if the scoring function was naive
- With only 64 validation examples (20% of my dataset), I needed to be careful about drawing statistical conclusions
I took this critique and created a structured analysis document with specific action items, including:
- Adding code to monitor and potentially adapt batch size based on profiling
- Implementing KL divergence monitoring with potential adaptive adjustment
- Adding component-level reward logging to detect gaming
- Enhancing evidence utilization reward to explicitly penalize irrelevant citations
- Implementing stratified validation split
- Adding additional metrics like F1 score, Expected Calibration Error, and Brier score
- Setting up statistical significance testing
Having this expert critique was invaluable. It helped me refine my approach before implementation and gave me more confidence in my strategic decisions. I constantly referenced the critique document throughout my implementation work.
When Hardware Reality Strikes
This is where things got… interesting. With all the theoretical work done and the expert critique incorporated, I was excited to start training. Saturday night at 9 PM, I kicked off what I hoped would be the first of many training runs.
The model completed the forward pass (generating outputs), but when it came time for the backward pass (learning from rewards), it crashed with an error:
/AppleInternal/Library/BuildRoots/d187755d-b9a3-11ef-83e5-aabfac210453/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPSCore/Types/MPSNDArray.mm:829: failed assertion `[MPSNDArray initWithDevice:descriptor:isTextureBacked:] Error: NDArray dimension length > INT_MAX'
Despite my laptop’s impressive 128GB of RAM, Apple’s Metal framework has a limitation where tensor dimensions can’t exceed INT_MAX (2^31 - 1). This is a hard API limitation, not a memory issue.
I tried everything:
- Reduced group size from 16 → 8 → 4 → 2
- Disabled mixed precision training
- Limited to a single training step
- Tried different optimization approaches
By midnight, I was tired and frustrated. I documented everything in a “practical issues” markdown file and asked Claude to write me a postmortem. Then I went to bed, disappointed.

Regrouping and Moving Forward
On Sunday, I took a walk in the park and thought about my options:
- Use an NVIDIA GPU instead (my gaming PC has an 8GB GPU - too small)
- Buy a new NVIDIA GPU (expensive and challenging to set up)
- Rent cloud GPUs (~$2,000 for a full training run)
- Write my own GRPO optimizer on top of Apple’s MLX ecosystem (it’s crazy that this was even considered a viable option - something that would never have been possible without AI assistance)
After discussing with colleagues, I decided that renting a cloud GPU workstation made the most sense. It would be cheaper than buying a new GPU upfront, and if the results looked promising, I could then invest in hardware.
The last 24 hours have been spent porting my code and setting up the cloud environment. There have been numerous challenges, but I’m making progress.
What I’ve Learned So Far
This experience has taught me several valuable lessons:
- Hardware matters: Despite “vibe coding” allowing me to tackle complex ML concepts, hardware limitations can still be showstoppers. Apple’s MPS backend for PyTorch has fundamental limitations for certain tensor operations needed in RL.
- Systematic exploration pays off: My thorough documentation of every failed attempt created a clear trail of evidence. This made it easier to understand the root cause and explore alternatives.
- Expert input is crucial: Getting a detailed critique of my implementation plan from outside experts was invaluable. It helped me identify potential issues before I encountered them and gave me confidence in my overall approach.
- Knowing when to pivot: Instead of endlessly fighting against hardware limitations, I recognized when to change course and explore cloud-based alternatives.
Next Steps
I’ve actually already completed the cloud setup since writing the first draft of this post, and wow - I ran into a BUNCH more issues that had me banging my head against the wall. But I’m saving those details for my next post in this series.
What I can say is that this journey has continued to test my resilience and problem-solving abilities. The cloud environment introduced its own unique challenges that weren’t present in my local setup. Working with remote GPUs, dealing with different CUDA configurations, and managing the training pipeline remotely all presented learning opportunities.
Stay tuned for the next installment where I’ll dive into these cloud computing challenges and whether I was ultimately able to get my RL training pipeline working properly. The saga of trying to teach a small model to reason better continues!
I’m particularly interested in whether a small 3B model can be enhanced through RL to close the gap with the larger 32B model, even if only on the Level 1 curriculum examples. As you might remember from my previous post, I designed a progressive curriculum starting with Level 1 (clear-cut cases with unambiguous evidence) before advancing to more nuanced scenarios. My strategy is to first prove RL can improve performance on these foundational cases before tackling more complex levels. If successful, this would provide a faster, more cost-effective solution for my hypothesis validation system.
The Continuing Vibe Coding Journey
Despite the setbacks, I remain convinced that LLM-assisted “vibe coding” is transformative for tackling complex domains. Yes, I hit a hardware limitation, but I was able to systematically troubleshoot it, document my findings, and pivot to alternatives—all without specialized ML expertise.
Instead of spending weeks learning the intricacies of GRPO or tensor operations, I could focus on the higher-level strategy and architecture. The LLMs handled the implementation details while I maintained the critical thinking needed to guide the process.
I’ll share more updates as the cloud-based training progresses. Whether this experiment succeeds or fails, the journey itself continues to reveal what’s possible when we combine human direction with AI assistance to break down technical barriers.
Stay tuned for Part 3, where I’ll hopefully have some exciting training results to share!