In my last post, I shared how my local reinforcement learning experiments slammed into a hardware wall. Despite my M4 Max’s impressive specs, Apple’s Metal framework proved inadequate for the tensor operations needed in RL training. After weighing my options, I decided to migrate to a cloud GPU solution—a decision that opened up a whole new adventure in debugging, optimization, and perseverance.
Setting Up the Cloud Environment
Having made the decision to rent cloud GPU resources, I methodically approached the migration. With Cursor’s help, I created a detailed checklist for setting up a remote development environment that would feel as seamless as my local setup:
- Procure a cloud instance with appropriate GPU (Lambda Labs)
- Configure SSH access and create friendly hostname aliases
- Set up VS Code remote extensions for seamless development
- Generate and configure GitHub deploy keys for repository access
- Install Python dependencies and environment configuration
- Run initial tests to validate GPU connectivity
The process seemed straightforward on paper. However, I immediately hit my first roadblock: I had accidentally selected an ARM64-based instance paired with a GH200 GPU. This meant I would need to compile PyTorch and TensorFlow specifically for this architecture—adding unnecessary complexity to an already challenging project.
After analyzing the tradeoffs, I decided to eat the cost and switch to a standard x86_64 instance with an H100 GPU. It was twice as expensive, but I’d already experienced enough friction. Sometimes, the most efficient path forward is to pay for simplicity.
Memory Mysteries: When 80GB Isn’t Enough
With my cloud environment configured, I eagerly kicked off my training run. The excitement quickly faded as I encountered yet another error—this time, a straightforward “out of memory” issue. Despite having 80GB of GPU RAM (technically less than my local 128GB, but now with the CUDA backend instead of Apple’s MPS), the model was still crashing.
Through debugging and profiling, I discovered the forward pass alone was consuming around 40GB. When backpropagation started, memory usage climbed even higher instead of releasing resources. My immediate suspicion: a memory leak in the GRPO trainer from the TRL library.
I tried several approaches:
- Monkey-patching the GRPO trainer
- Forcing garbage collection
- Reducing batch sizes
- Investigating the source code
After hours of frustration, I nearly gave up. Then I noticed something interesting—the TRL GitHub repository had numerous recent commits addressing memory optimization and GRPO improvements. One particularly caught my eye: vLLM integration.
Instead of fighting with the release version, I decided to go straight to the bleeding edge. I updated my requirements to use the latest main branch and refactored my code to leverage vLLM (a virtualization layer for LLM generation).
The key insight came when I realized many projects were running VLLM on separate machines. Instead, I configured vLLM to use only 30% of the available memory, leaving the remainder for the GRPO trainer. This was the unlock—my model finally started training without memory errors!
The Curious Case of Zero Rewards
Just when I thought I’d cleared the final hurdle, I noticed something odd in the Weights & Biases dashboard—my model was training, but the rewards were consistently zero. Something was still wrong.
The issue turned out to be in how I was parsing the model’s outputs. When I compared my evaluation code with my training code, I discovered they were using completely different paths to extract the decision classes (VALIDATED, REJECTED, etc.).
I spent hours consolidating these code paths to ensure consistency, but the problem persisted. Frustrated and exhausted, I put the project down late Tuesday night.
Breakthrough via Debugging
The next evening, I took a step back and decided to tackle the problem differently. Instead of running the full training pipeline, I set up remote debugging to place a breakpoint directly in the reward function. This allowed me to walk through the call stack and inspect what was actually happening.
The revelation was immediate—the completions being sent to the reward function were tiny. So small, in fact, that they only contained the “reasoning” portion of my expected output format (reasoning → decision → confidence), with the actual decision class completely missing! That’s why my parser was returning “UNKNOWN” for every sample.
But why were the completions truncated? After more extensive debugging and inspecting variables, I discovered the silliest error imaginable: a command-line argument was overriding my default max token setting. Instead of generating 1024 tokens, the model was limited to just 64 tokens—a value I’d likely set while troubleshooting memory issues earlier.
The fix was trivial: changing a single number from 64 to 1024. With that simple change, everything started working. The model began generating proper completions, the reward function correctly classified them, and actual learning began to take place.
Finally Running!
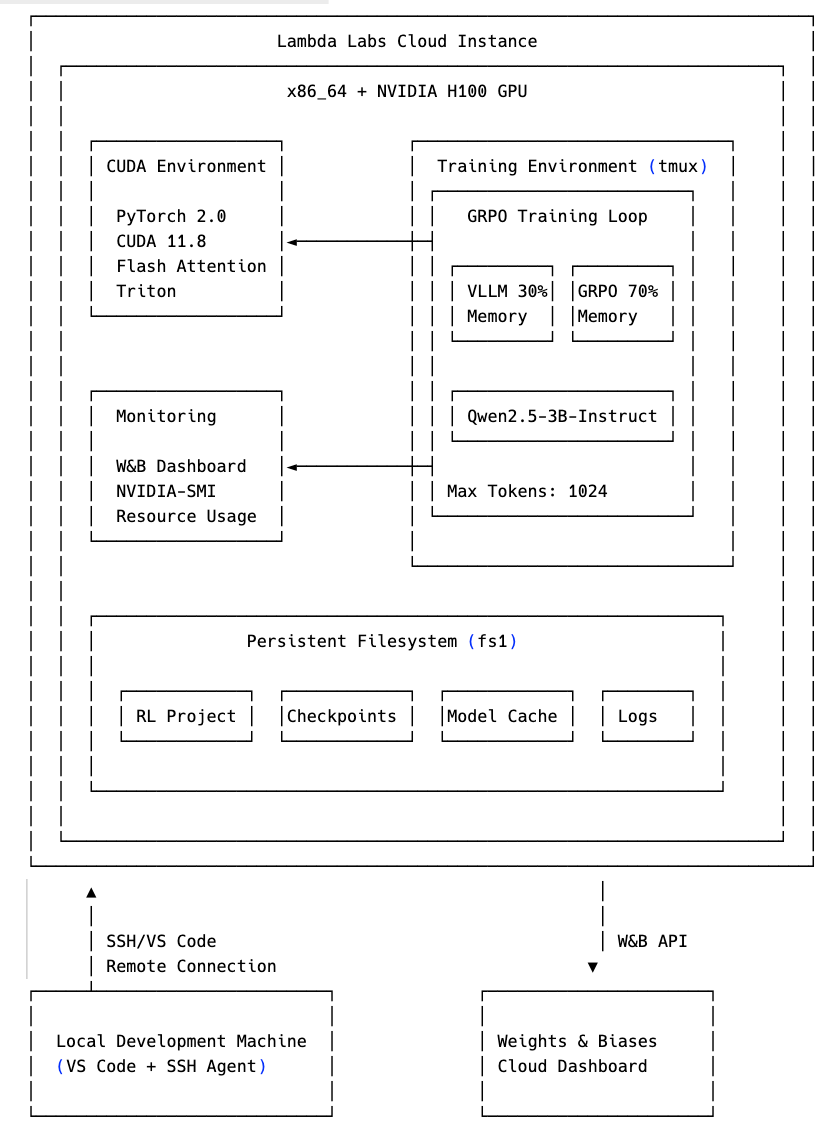
Last night, I watched with immense satisfaction as my training run successfully processed batches, generated appropriate rewards, and started updating the model weights. After verifying everything was working correctly for an hour, I launched a full training run in a tmux session and detached, allowing it to run overnight.
As of this writing, the training has been running for nine hours without issues. Just having a stable training pipeline feels like a massive victory after all the challenges.
Early Results: Promising Signs
While I haven’t performed out-of-sample evaluation yet (which will be critical for drawing final conclusions), the metrics from Weights & Biases dashboard show remarkably encouraging trends:
Performance Improvements
- The normalized reward values have increased from ~0.5 initially to ~0.8 after 9 hours—a 60% improvement
- Even more telling, the standard deviation in rewards has decreased from ~0.45 to ~0.25 (44% reduction), indicating the model is producing more consistently high-quality outputs
- The model has completed approximately 95 global steps, with a learning rate decaying linearly from 4.9e-6 to 4.4e-6
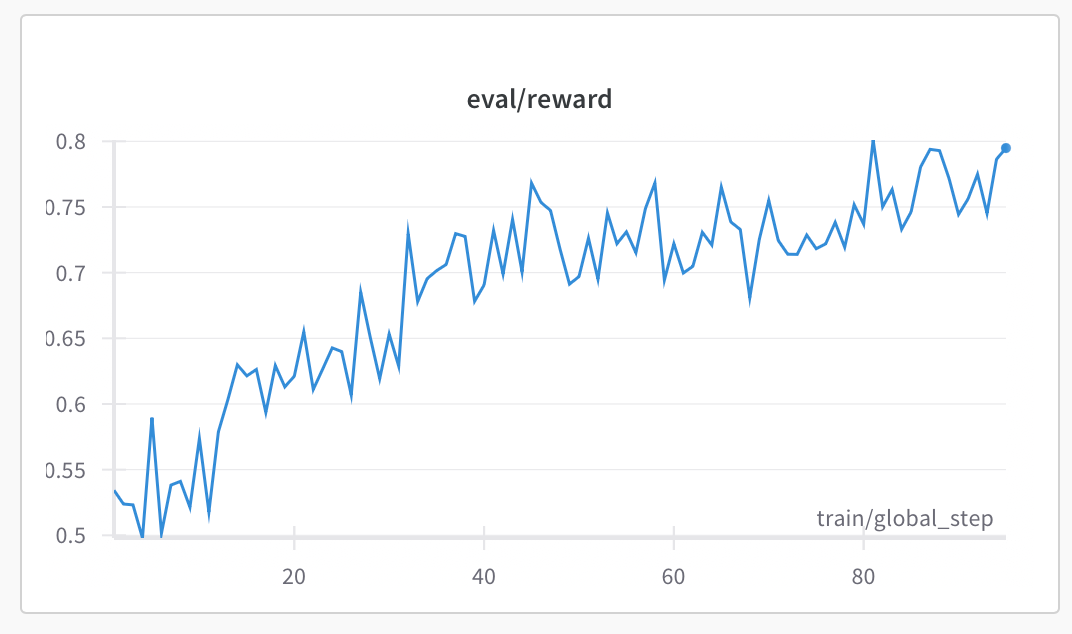
Figure 1: Reward values steadily increasing from ~0.5 to ~0.8 over 95 training steps, with consistent upward trajectory despite expected oscillations.

Figure 2: Decreasing standard deviation in rewards, showing the model producing increasingly consistent outputs.
What’s particularly exciting is that the improvement trends remain strong with no evidence of plateauing. The reward values continue to show consistent upward movement, with expected oscillations but reaching peak values in the latest steps (80-95).
These early indicators suggest GRPO is successfully teaching our 3B model to align with the reward signals we designed. The decreasing variance paired with increasing rewards is exactly the pattern we’d hope to see in effective reinforcement learning.
Perhaps most importantly, these improvements in reward metrics are translating to real accuracy gains. As shown in Figure 3, the running average accuracy has climbed from around 60% to approximately 82% - significantly closing the gap with our 32B model’s 83% performance on the same dataset.
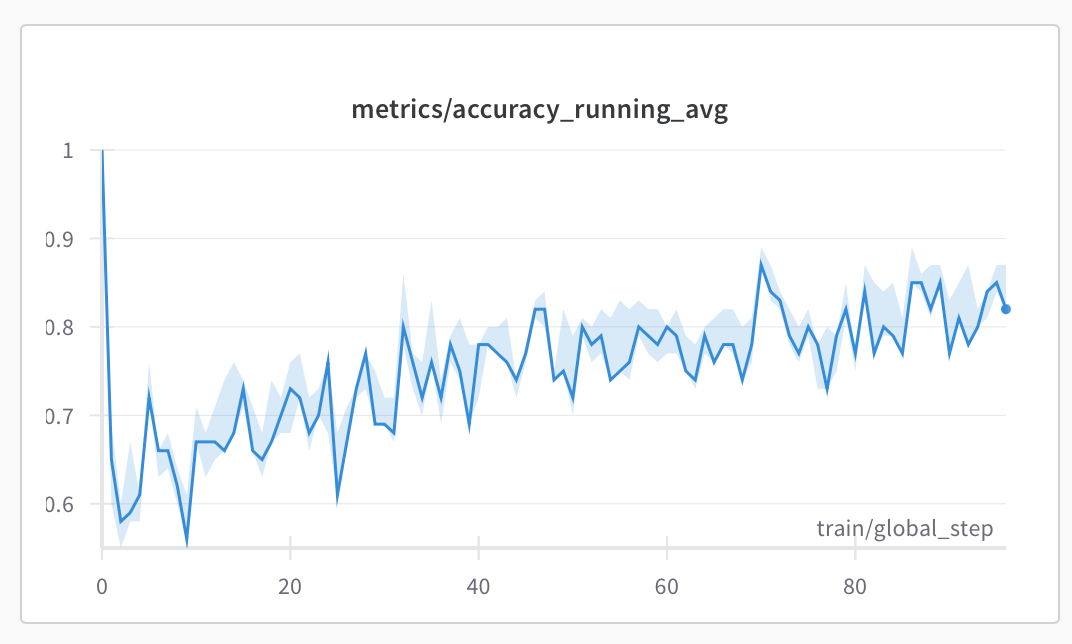
Figure 3: Running average accuracy improving from ~60% to ~82% over training, with confidence intervals shown in light blue.
Of course, I’m tempering my excitement until I can run proper validation tests. I’ll need to:
- Evaluate against held-out data to check for overfitting
- Compare checkpoints qualitatively (2-hour vs. 8-hour vs. current)
- Manually inspect sample outputs to verify the metric improvements translate to actual quality enhancements
Based on current trends, I’m planning to continue training for at least 50-100 additional steps to see if and when the metrics plateau. I’ve been capturing checkpoints at regular intervals (2 hours, 8 hours) to ensure we can compare different stages of the model’s evolution.
Lessons Learned (So Far)
This phase of the project has taught me even more valuable lessons:
- Environment consistency matters: Different environments can introduce subtle incompatibilities that are difficult to debug. Consolidating code paths and ensuring consistency across evaluation and training workflows is crucial.
- Remote debugging is essential: Being able to set breakpoints and inspect variables in the cloud environment saved countless hours of guesswork.
- Modern ML requires resource management: Even with 80GB of GPU memory, efficient resource allocation between the model, generation, and optimization components is critical.
- Persistence pays off: The solution to a multi-day debugging nightmare turned out to be a single number change. Persisting through the frustration ultimately led to success.
- Sometimes the bleeding edge is better: In rapidly evolving libraries like TRL, the latest development version can sometimes be more stable and efficient than the release version.
What’s Next
The early results have reinvigorated my original hypothesis: reinforcement learning could indeed help our 3B model close the performance gap with the 32B model, at least on the Level 1 curriculum examples. The smooth progression of reward metrics suggests stable training dynamics, and the reduction in reward standard deviation paired with increasing rewards is a particularly positive indicator.
However, there are potential challenges to watch for:
- Overfitting (which validation testing will reveal)
- Reward hacking behaviors that might appear in qualitative analysis
- KL divergence issues if we continue training significantly longer
- Economic viability: This experiment has already cost $280 in cloud GPU resources ($237.51 for the main H100 training instance alone, running at $2.49/hour). For perspective, that same $280 would get me approximately 3,733 evaluations using OpenAI’s O1 model (assuming 1000 input and 1000 output tokens per evaluation) - enough to run my entire test suite multiple times.
My immediate next steps include:
- Complete validation testing with the latest checkpoint
- Document specific examples of model improvement
- Prepare for potentially extending the training run based on validation results
- Consider A/B testing between the 8-hour and current checkpoints for specific use cases
- Calculate the total cost-performance tradeoff to determine practical scalability
In my next update, I’ll share the comprehensive results and whether this entire ordeal has been worth it. Can RL training make a 3B model competitive with a 32B model for specific tasks? Could it even (fingers crossed) make our small model competitive with frontier models like OpenAI’s o1 on our narrow use case? And would the compute resources required make this approach practical for real-world applications? With costs approaching $300 for this initial experiment, the economic question is just as important as the technical one.
Stay tuned for Part 4, where I’ll analyze the final results and determine if this experiment has justified all the technical challenges!
The vibe coding journey continues, demonstrating both the power and limitations of using AI assistance to tackle complex ML projects without specialized expertise. Despite the setbacks, I’ve been able to navigate through implementation details that would normally require weeks of dedicated study—a testament to how this approach can democratize access to advanced techniques.