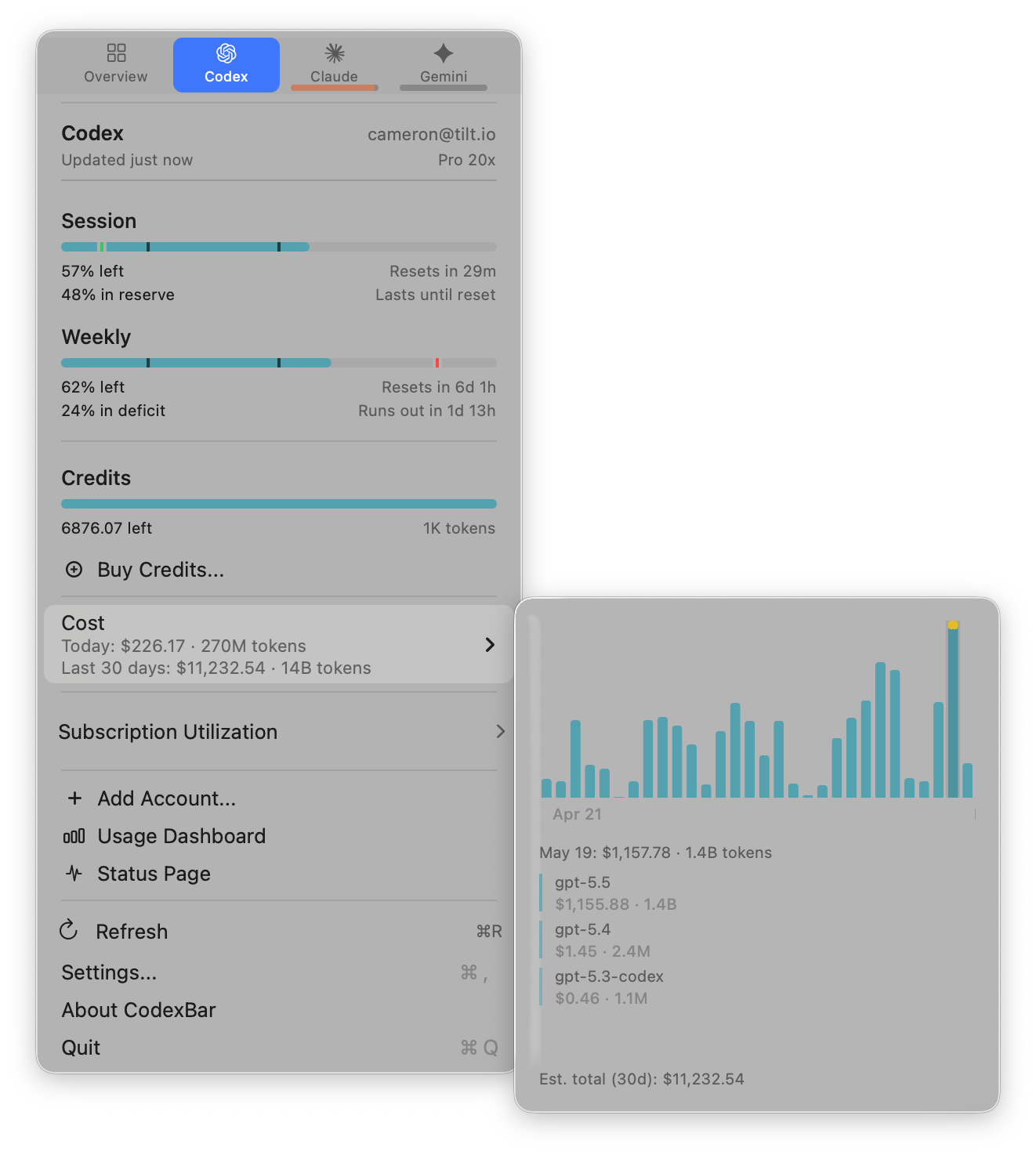
My 30-day token bill is $11,232.54. Fourteen billion tokens, almost all of it GPT-5.5 on a ChatGPT Pro 20x plan. Yesterday alone I put $1,157.78 and 1.4 billion tokens through the harness. Today, mid-afternoon, I’m already at $226 and 270M.
That’s nothing next to Peter Steinberger: $1.3M and 603 billion tokens against the OpenAI API in 30 days. Peter noted in replies that disabling fast mode would cut that ~70%, so the comparable number is closer to $390k. Either way, a different category: Peter has described his stack publicly, running ~100 Codex instances in the cloud doing PR review, security scans, issue de-duplication, performance benchmarks, meeting listeners that auto-start PRs. His framing question: “how would we build software in the future if tokens don’t matter?” Mine is $11k at standard rates, no fast mode, exclusively me at the keyboard. Interactive development, one driver, fifteen sessions in flight. Every thousand of that bill correlates one-to-one with shipped output: PRs merged, features in production, cycle times I can measure.
There is a new performance class in software engineering, and it is already pulling apart into something more like F1 than the old IC ladder. The skill isn’t prompting. The skill is driving 10–15 concurrent agents across multiple projects without crashing any of them. I think I’m in that class, and I’m a little afraid of what that means.
What this actually looks like
On a normal day I’m running five parallel tracks per project, across three projects. Fifteen agents in flight, give or take. Each one has its own code review loop, its own test harness. (I’ve since written up the loops I actually run.)
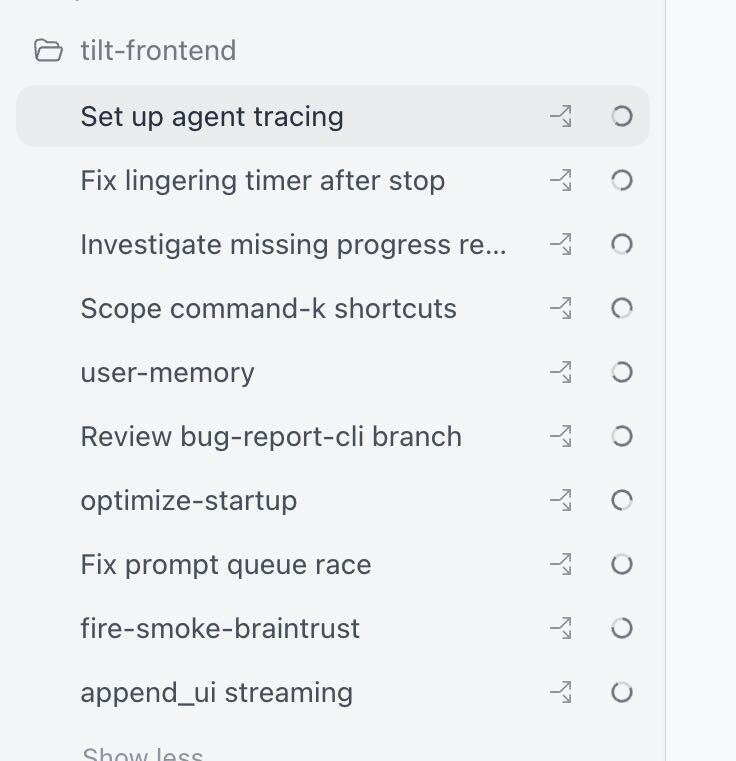
That’s ten on one project. Add the other two repos and I’m in the 10–15 range. The meta is constant, per thread:
- Is the codebase shaped right for what this agent is doing?
- Does it have enough context?
- Does it have the right feedback mechanism (tests, API keys, dev creds, something real to validate against)?
- Where’s the iteration loop slow, and can I shorten it?
- What did I learn here that I should fold into the next session?
As you turn up the concurrency, the probability that something is going wrong at any given moment converges to one. There’s always something to check, always feedback to give.
The closest thing I’ve felt to this before was running a product org as it scaled from under ten to fifty to seventy-five people. Past about fifty, there was a human crisis somewhere every single day. My calendar was solid. I’m now feeling the same nervous-system load with 10–15 agents instead of 75 humans. I’m getting better at it. The models and the harness are too. That fusion is the cyborg part.
The new grading rubric
When I was a software architect at Autodesk (the role they’d now call distinguished engineer), there were a handful of real 10x developers on the graphics and systems teams. I watched specific people, more than once, do more in a day than the rest of us did in a quarter. I’d sit there in awe.
This isn’t another 10x story. Those guys were graded on raw output. The new class is graded on different dimensions:
- How many agents can you effectively manage at once?
- Are the outputs usable, or just demos?
- Will the people who depend on you accept what you ship?
- Are you thinking about ops, on-call, regressions, or just throwing prototypes over the wall?
- Will you put your name on the bug fixes for the next year and stake your reputation on it?
Operator-class, not IC-class. Exceptional driver in exceptional machine, neither alone is enough.
The team behind the driver matters too. The engine team is whoever’s training the model. The controls team is broader than the harness vendors (Codex, Claude Code, Cursor): it also includes everything my company has built around them. Fast CI. API-accessible logs (Vercel). Metrics (Grafana). Databases (Supabase). The internal skills and scripts that let agents iterate without me holding their hands. When Phil ships a unified search across our GCP logs, he’s the trackside tire engineer delivering an upgrade between sessions. I’m the driver, doing sim runs and leveling up. Not solo work, even if the seat is single-occupancy.
The spec ops frame
Dan Shapiro maps AI-assisted programming onto a driving-automation ladder. Level 0 is spicy autocomplete. Level 2 is pair programming where you review every line (Shapiro thinks 90% of “AI-native” devs are stuck there). Level 4 is engineering manager for a team of agents. Level 5 is the dark factory: nobody reads the code, ever.
The cleanest Level 5 example is StrongDM’s AI Factory: “code must not be written by humans, code must not be reviewed by humans.” They built a digital-twin universe of cloned Okta, Jira, and Slack so agents can iterate against fake APIs at unlimited volume. Their bar is $1,000 of tokens per engineer per day. Simon Willison wrote about it skeptically: interested, but flagging the economics and the proof-of-correctness question.
I’m not on this ladder, or at least not cleanly, and the F1 frame is why. The ladder is about industrialization: known problems, repeatable processes, scaling a knowable spec into shipped code. “Clone Slack” is a known spec. My work is the opposite shape: 0-to-1 discovery. The questions I get pulled into look like “what does AI in finance actually look like a year from now?” There’s a destination, but no map. Beach landing with a compass, working out the route to the mountain top by walking it.
The agents aren’t industrializing a plan; they’re helping me run the experiments that surface the plan. One thread’s signature, from a session that’s still open as I write this: it started May 15 as “I’m thinking of embedding marimo notebooks as a new asset type. Is marimo the right tool?” Five days later it had become a feature gated behind a PostHog flag, in an open PR. In between: 607 million tokens, 46 messages from me, 530 patches from the agent across 160 files, 37 self-initiated context compactions, and 18 web searches the agent ran on its own (marimo docs, Vercel v0 sandbox, Material Design tabs, PEP 723). There was a three-day gap in the middle while I worked on something else. That’s one of fifteen sessions in flight.
Peter is solving a different version of the same problem: industrialize the scaffolding around the product (PR review, triage, security, ops, meeting listeners, ephemeral environments) so his human attention stays on OpenClaw itself. His Level-5 spend lives in the scaffolding layer.
The projects I get pulled into are small, high-concurrency, high-stakes, on terrain nobody’s mapped. Spec ops territory. A colleague described one rescue exactly that way: “calling you in is like calling the spec ops.”
Maybe most code eventually gets built Level 5. The work I get pulled into looks like reconnaissance, and I suspect it’s a durable category.
Holding down the shutter
Jason Fried posted this the same week I was drafting this post:
Bragging about how much software you’re shipping with AI is like holding down the shutter button and bragging about how many photos you took.
Volume isn’t proof of taste. 14 billion tokens could just as easily be 14 billion bad decisions. The Fried version is sharper than the lazy “you’re not really coding” line, and it deserves an answer.
There’s a famous ceramics-class parable from Art & Fear: a teacher splits a class in two, grades one half on quantity and the other on quality, and the quantity group produces the best work. The underlying claim that iteration beats single-shot perfection has held up across most creative domains I know about. Great photographers do hold down the shutter button. Then they pick winners. Their volume went vertical with digital, and their craft didn’t drop. The iteration loop got tighter, and the selection skill became the actual skill.
More iterations plus better selection equals better work. The selection is where the work moved. Hold down the shutter and never pick winners, Fried’s right about you. Pick winners (tell which of three concurrent runs solved the problem and why), and the volume is doing real work.
There’s a portfolio-strategy version of the same argument. A founder used to need irrational confidence to bet on one idea; VCs hedged that by holding many bets where one winner paid for nine misses. Concurrent-agent work feels like that pattern compressed down to a single operator: I run five experiments in parallel because four will fail and one will be the answer, and I can’t tell in advance which. That dynamic used to require capital. Now an IC can do it with tokens. Whether that stays at the IC layer or quietly recompiles into team structures, I don’t know.
This doesn’t fully refute Fried’s critique, and it shouldn’t. Tons of output doesn’t automatically mean good. But it might, for the reasons above. I’m staking my reputation on that “might” carrying the weight.
What I’m afraid of
Could everyone at my company spend $11k/month on tokens? Obviously not, not today and not at list. The spend that makes me an F1 driver is partly a subsidy. When the subsidies end, or when the price gets another zero on it, what’s left of this skill class?
The closest prior I have is the VP of Engineering or CTO at a public company “betting on TypeScript”: a single technical decision controlling orders of magnitude more capital than the average IC. The pattern has existed for decades; the novelty is which layer it’s landing on. Token budgets in the $10k–$1.3M range are landing in IC hands. Either that gets clawed back when the subsidies end, or what we used to call “IC” quietly becomes a capital-allocation role.
The bet only breaks if two things happen at once: token prices climb (call it 3x) and model quality stops improving fast enough that cheaper tiers can do what the frontier does today. One without the other and the math still works. A manager of seven engineers already allocates around $1.4M/year in capital without anyone calling it exotic.
One wrong turn in this regime crashes a multi-million-dollar vehicle. A careless weekend at this concurrency burns more capital than a month of my old career did. The wreckage is wasted tokens and broken trust.
Where I land
I think I’m an F1 driver. I’m having more fun than I’ve ever had in this career. I can’t imagine going back.
The car I actually learned to drive in was a black Volkswagen Jetta, manual transmission. My brother had to test-drive it and bring it home for me because I didn’t have my license yet, and I was specifically afraid of the stick. The F1 thing is the same shape of fear, three orders of magnitude up.
Process note: Drafted from a voice memo. Used Claude Code for transcription cleanup and structural editing. Token-spend numbers, session traces, and tweets were verified by me. The Shapiro ladder and the StrongDM/Simon Willison framing are prior thinking I’m building on; the spec-ops reframe and the F1 claim are mine. All claims are mine; mistakes are mine.